Филологи, литературоведы и историки издавна изучают переписки разных выдающихся личностей, писателей и политиков. Иногда в этих переписках удаётся обнаружить ранее неизвестные детали жизни авторов писем и их окружения или, например, понять причины тех или иных произошедших событий. Однако, чтобы обработать всю корреспонденцию, сохранившуюся с 18-19 веков, вручную, требуется приложить огромные усилия и потратить настолько же огромное количество времени. Более того, со временем вскрываются новые источники, потомки известных людей находят письма своих предков. Таким образом, изучение корреспонденции становится фактически бесконечным процессом, ведь материал всё прибывает и прибывает.
Проект "Facebook of the past" задумывался, во-первых, как автоматизация этого процесса. Если бы компьютер мог самостоятельно обрабатывать письма в электронном формате, извлекая всю необходимую информацию и систематизируя их, это бы значительно уменьшило нагрузку на учёных и позволило бы им заниматься, собственно, изучением писем. Во-вторых, важной целью проекта было представление корреспонденции писателей в таком виде, чтобы с её помощью можно было получить представление о конкретном дне или персонаже в истории. Отсюда название проекта, "Facebook of the past": выбирая конкретный день, человек может увидеть все письма, написанные тогда, и, пролистав их друг за другом, получить более полную картину событий, произошедших в этот день. Также одной из целей была реализация большой социальной сети, которая ясно отражала бы социальные связи и контакты как между современниками, так и между людьми, жившими в разное время.
Использовалась корреспонденция следующих писателей:
Руководители:
Участники:
I этап. Создание корпуса писем.
Каждым членом команды была выгружена корреспоненденция одного из авторов с сайта feb-web.ru или rvb.ru. Создание корпуса для каждого писателя происходило автоматически: каждое письмо сохранялось в отдельный текстовый файл (расширение .txt), предварительно пройдя очистку от html-тегов, информации о дате и месте назначения письма, а также от редакторских пометок, сносок и комментариев. В некоторых случаях письма внутри корпуса были классифицированы по авторам/адресатам.
II этап. Автоматическая обработка и систематизация корреспонденции в виде базы данных.
В ходе выкачивания корреспонденции параллельно создавалась база данных со сводной информацией обо всей имеющейся корреспонденции. Для каждого письма из html-тегов и просто из текста письма извлекалась следующая информация:
а также
Универсальной программы для обработки корреспонденции на данный момент не существует, так как набор html-тегов для каждого писателя различается и пока не удаётся оптимизировать программу под все наборы тегов, однако, общая схема незначительно отличается от случая к случаю и понять её принцип можно, вглянув на любую из написанных программ (см. исходный код проекта внизу страницы).
Создание единой схемы датировки писем.
Важной частью этапа обработки стало создание единой схемы датировки писем. Очевидно, что разные писатели по-разному оформляли даты в своих письмах и даже после ручной обработки этих писем составителями собраний сочинений, даты всё равно не унифицированы во всей имеющейся корреспонденции. Также, стоит отметить, что часто даты бывают указаны неточно (в случаях их восстановления филологами и историками): может быть указана только часть года или месяц. Всё это требовало унификации дат, в том числе и для того, чтобы возможно было воплотить ту часть проекта, которая требовала отображения корреспонденции, датированной конкретным днём. Схему датировки писем и пояснения к ней можно найти в самом низу страницы.III этап. Нахождение "упоминатов" в письмах и связывание всех участников переписки с их страницами в Википедии.
В рамках проекта было придумано понятие "упомината", то есть некоего человека, упомянутого в переписке. Следующим этапом работы стало написание программы, находящей упоминатов в письмах и создающей базу данных с "активностью" различных личностей в рамках переписки. Для каждого участника указывалось количество упоминаний в письмах других участников переписки, количество писем, написанных им и ему. Далее, каждый человек из базы данных участников был найден в одном из доступных указателей имён (для того, чтобы у нас были полные имена, а не только, например, имя и отчество) и затем связан со ссылкой на свою страницу в Википедии, если таковая имелась. Последнее было сделано для того, чтобы пользователь, работающий с нашим корпусом и базами данных, имел возможность получить необходимую информацию по любому участнику, не прилагая больших усилий на поиски.
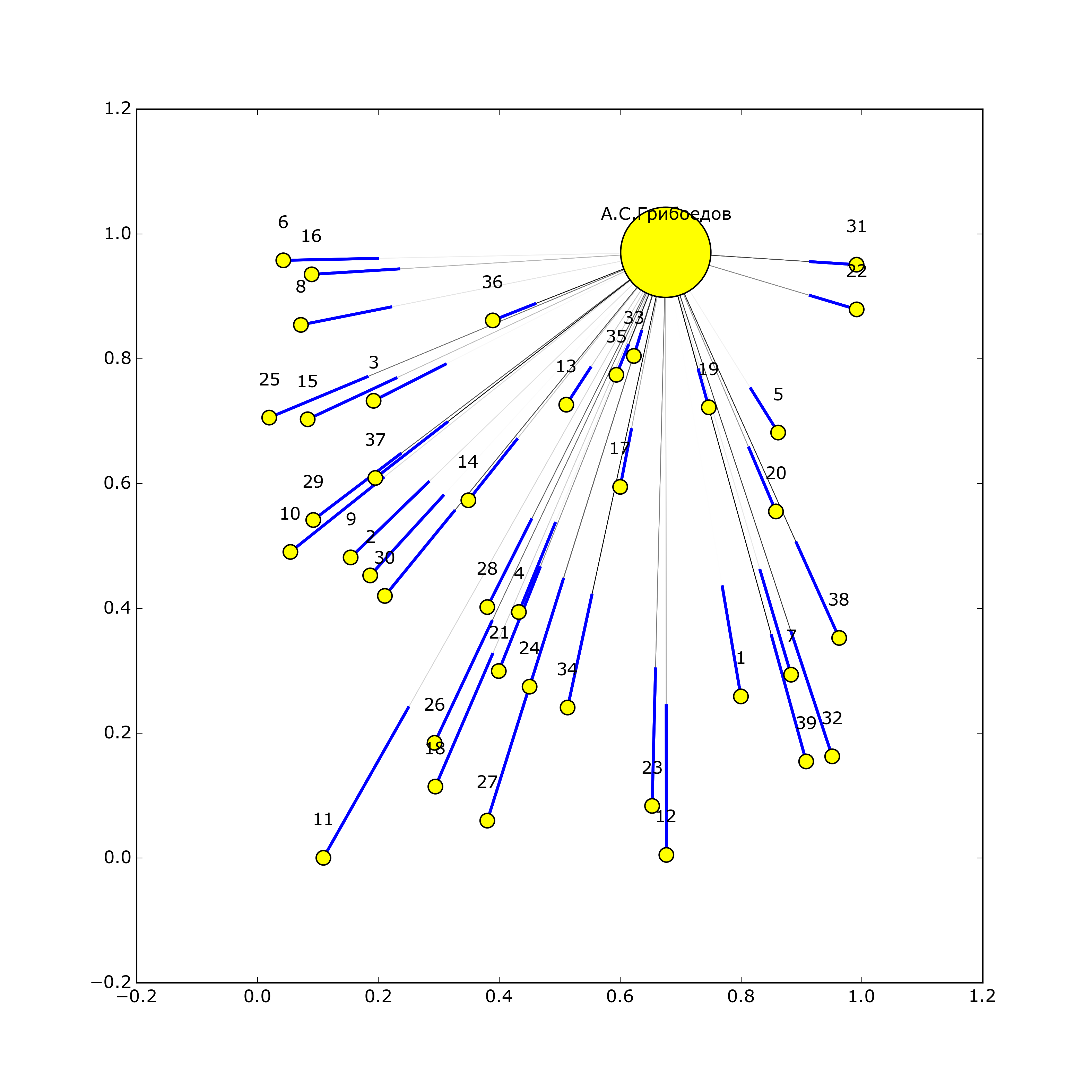
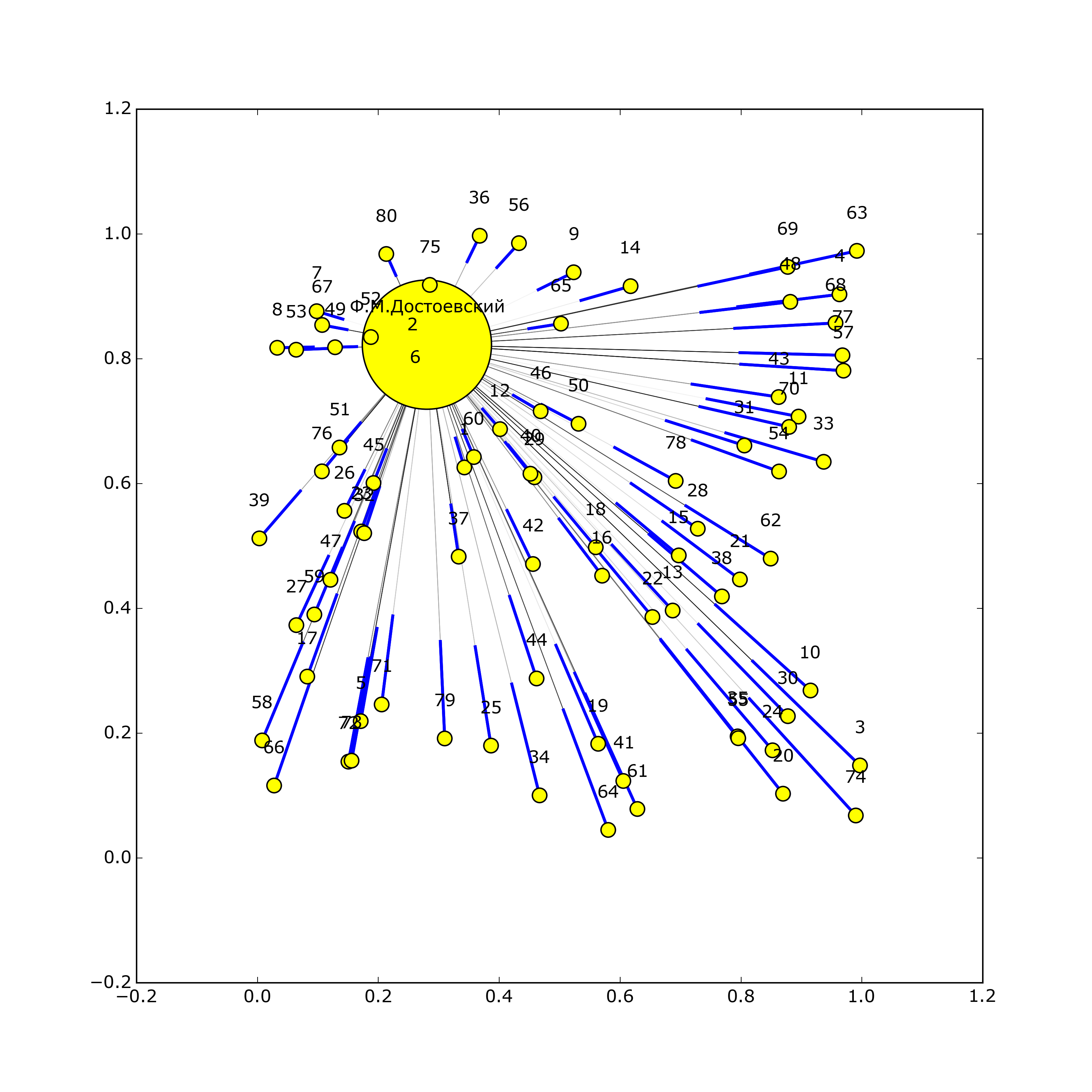
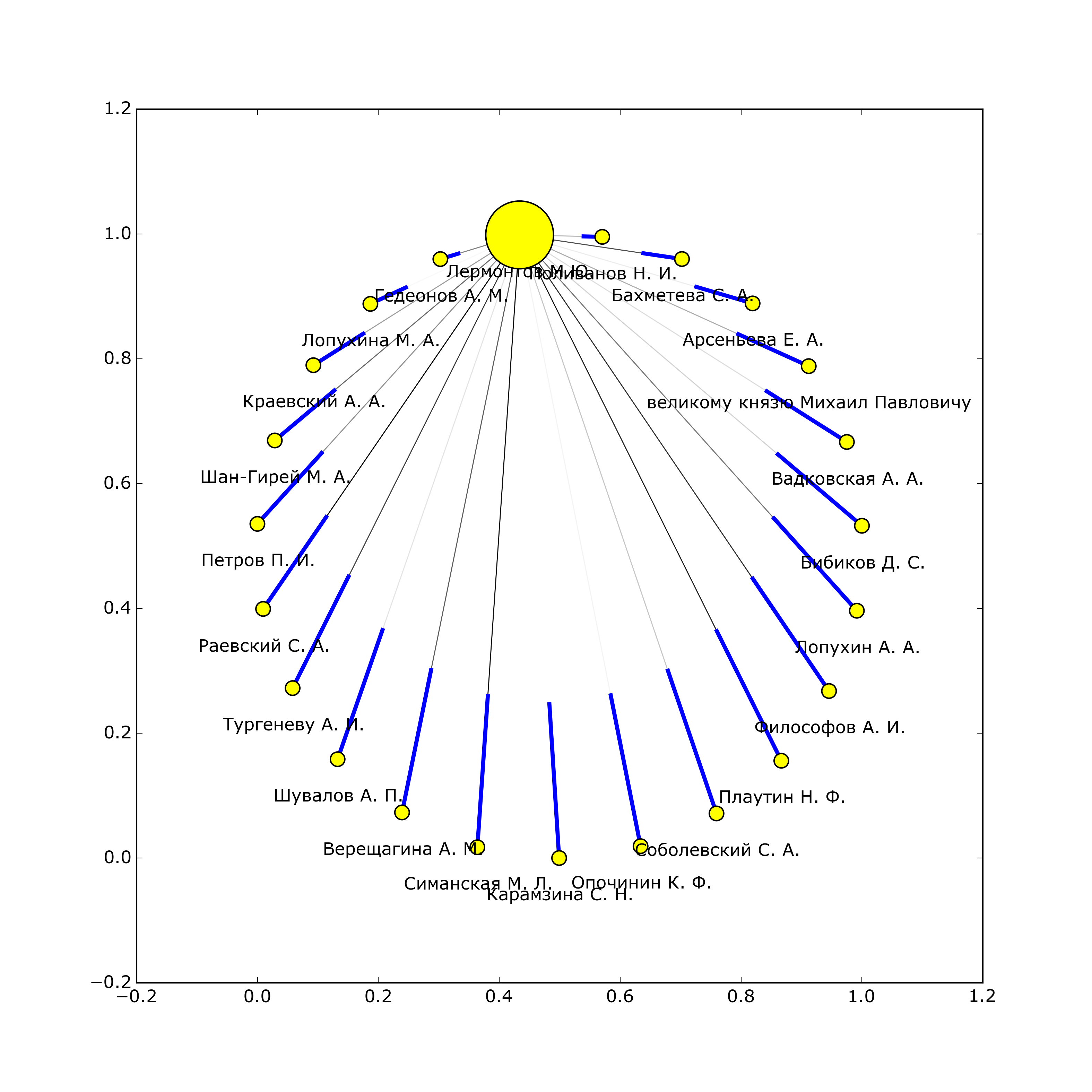
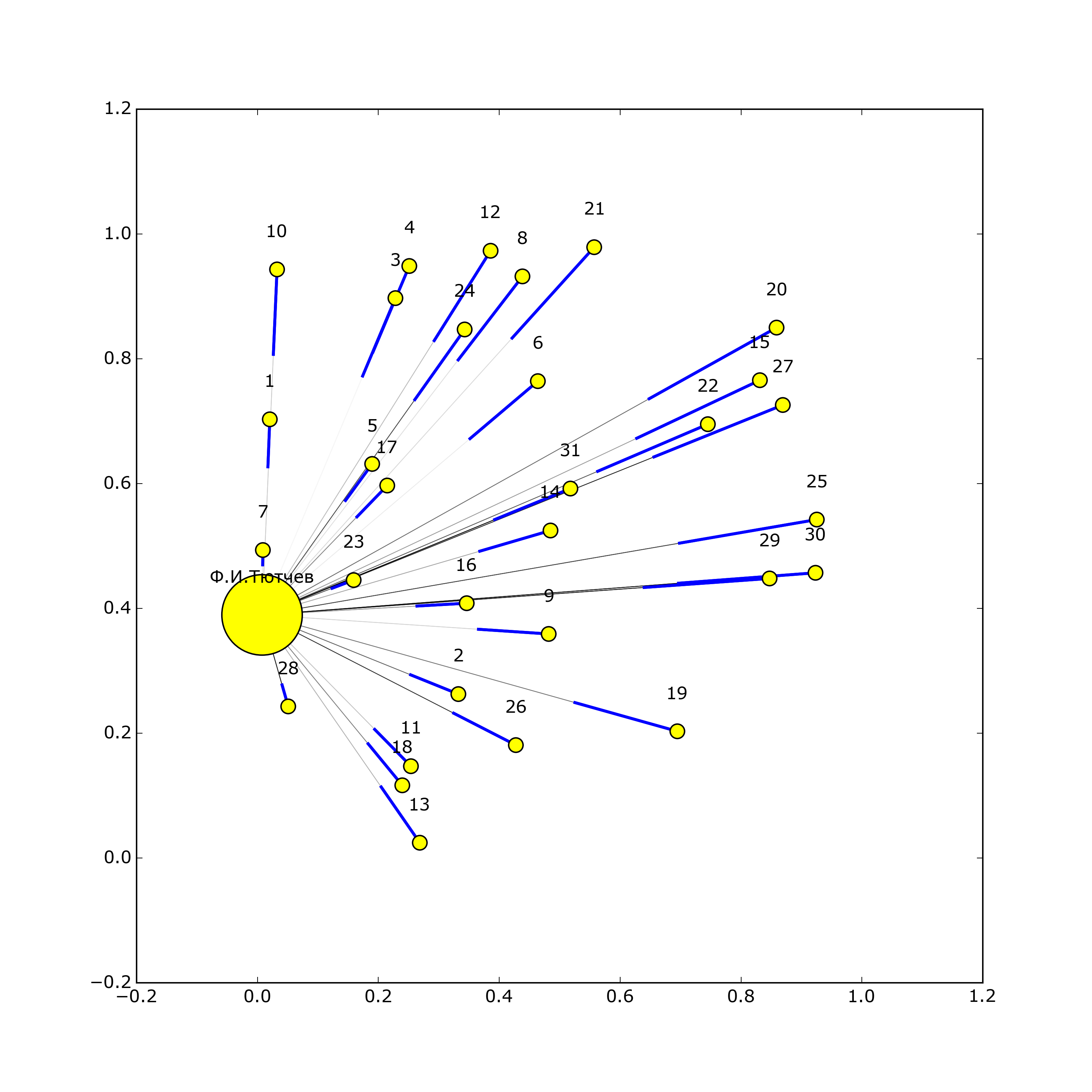
IV этап. Создание взвешенного графа социальных связей между участниками переписок на основе базы данных.
Наконец, последним этапом работы стало создание графа социальных связей между участниками переписки с помощью библиотек networkx и matplotlib. Как было сказано выше, для каждого человека записывалось количество его упоминаний в чужих письмах, а также писем, написанных им и ему. Вес каждого из этих пунктов был разным и, соответственно, по-разному учитывался при построении взвешенного графа. Каждый узел в графе соответствует одному человеку, размер узла - количеству людей, с которыми он поддерживает контакт, толщина ребра между узлами - количеству писем, написанных людьми друг другу. К каждому созданному графу прилагается также небольшая аналитика с указанием основных характеристик этого графа.
Грибоедов Александр Сергеевич
{kind=link}


Достоевский Фёдор Михайлович
{kind=link}
Лермонтов Михаил Юрьевич
{kind=link}


{kind=link}
Шолохов Михаил Александрович
{kind=link}

Обработка корреспонденции (включая создание базы данных и архива писем):
Создание единой системы датировки писем;