Анализатор частей речи работает на основе машинного обучения с частичным привлечением учителя (semi-supervised learning). Такое обучение предполагает, что, не имея размеченных данных, мы размечаем какую-то часть данных с помощью машинного обучения без учителя (unsupervised learning), а затем используем полученные размеченные данные для обучения другого алгоритма (supervised learning).
Для машинного обучения без учителя был использован алгоритм агломеративной иерархической кластеризации. Этот алгоритм умеет работать с большими данными и на основании функции близости умеет организовывать кластеры, различающиеся по размеру, что является важным для частеречной разметки, так как части речи распределены не одинаково.
Для машинного обучения с учителем был использован простой алгоритм линейной классификации. Чтобы реализовать обучение такого алгоритма, мы составили тестовый файл из 11500 словоформ, который кластеризовали на 9 классов. Далее размеченный текст подавался на обучение линейному классификатору, который размечал все тексты амхарского корпуса.
В амхарском языке имеются закрытые классы частей речи (местоимения, адлоги, союзы, частицы), которые могут плохо выделяться с помощью машинного обучения, так как для них отсутствуют какие-либо признаки. Именно поэтому анализатор частей речи представляет собой гибридную модель, которая сочетает модель обучения с частичным привлечением учителя и набор правил, связанных с поиском словоформы в словаре зарытых классов слов и в словаре амхарского языка. Такая модель при анализе словоформы в первую очередь прибегает к правилам и, если правилами не удается классифицировать словоформу, то алгоритм предсказывает класс на основании линейного классификатора.
Признаки для обучения алгоритмов кластеризации и классификации основываются на морфологической и синтаксической информации о словоформе. Морфологическая информация представляет собой поиск определенного форманта в словоформе. Кроме того, в качестве дополнительной морфологической информации в признаки включается информация о количестве гласных определенного порядка (всего так называемых порядков в амхарском шесть), так как для амхарского языка характерна внутренняя флексия, особенно для глагольных форм («советовать»: መከረ - mɛkkɛrɛ – прошедшее время (исходная форма глагола); ይመክራል - yəmɛkral – настояще-будущее время; መክሮ - mɛkro – деепричастие; ምከር - məkɛr – повелительное наклонение; ይምከር - yəmkɛr – желательное наклонение). Синтаксическая информация связана с порядком слов в предложении: отмечается является ли слово первым или последним в предложении. Более того, в качестве дополнительных признаков мы рассматривали длину слова, длину предложения (оказался нерелевантным признаком), наличие рядом со словом знака препинания. Признаки для обучения были сгруппированы по классам с одинаковой грамматической семантикой, например, указание на рефлексив, объектный суффикс и т.д. В таком случае, наличие одного форманта из группы маркировалось как единица, а отсутствие – как ноль.
Алгоритмы кластеризации и классификации были написаны на языке программирования Python с использованием модуля для машинного обучения scikit-learn.
Для расчета качества алгоритма частеречной разметки использовался золотой стандарт из 103 амхарских словоформ, размеченных вручную. F-measure алгоритма составляет 0.59, accuracy – 0.68.
Ниже представлен график, на котором визуализированы ошибки выбранного нами алгоритма частеречной разметки.
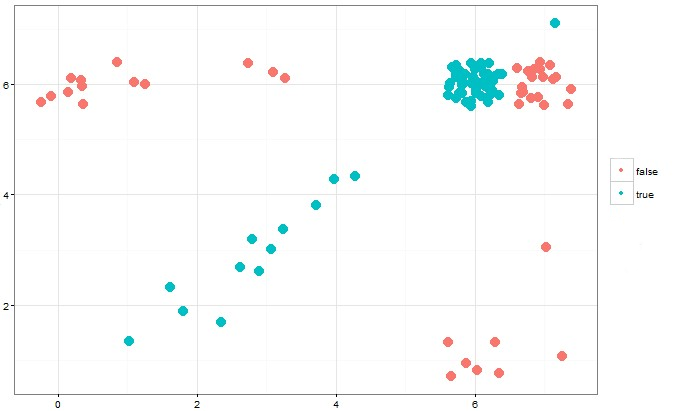
Из графика видно, что наибольшую сложность для алгоритма представляют прилагательные и глаголы, так как для них наиболее характерна внутренняя флексия, которую довольно сложно отслеживать автоматически. Кроме того, сложность возникает в определении союзов, так как союзы в амхарском языке часто бывают омонимичны адлогам. Из этого, можно сделать вывод, что, вероятно, частеречную разметку можно улучшить, обратив внимание именно на эти части речи, на их морфологическую и синтаксическую информацию.